
Essential Sorting Algorithms
Understanding and Implementing sorting algorithms


Sorting algorithms are crucial for arranging data in order, either ascending or descending. Choosing the right sorting algorithm affects the performance of applications based on factors like dataset size and available resources. This guide covers various comparison-based sorting algorithms, focusing on:
Description: An explanation of how each algorithm works.
Use Cases: Ideal scenarios where each algorithm performs best.
Complexity: The time and space complexities that affect the algorithm's efficiency.
Benefits: Advantages of using the algorithm.
Drawbacks: Limitations or scenarios where the algorithm may not be suitable.
1. Bubble Sort
Bubble Sort repeatedly compares adjacent elements and swaps them if they are in the wrong order. It continues this process until the list is sorted.
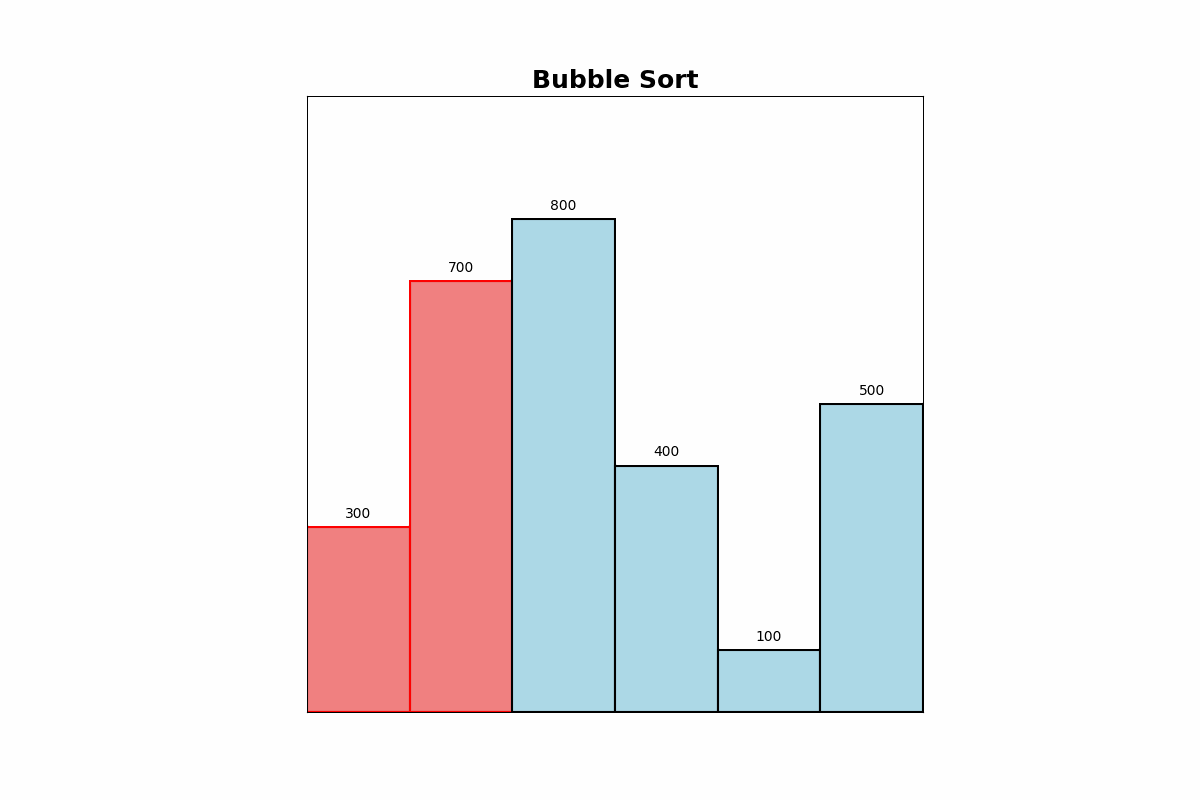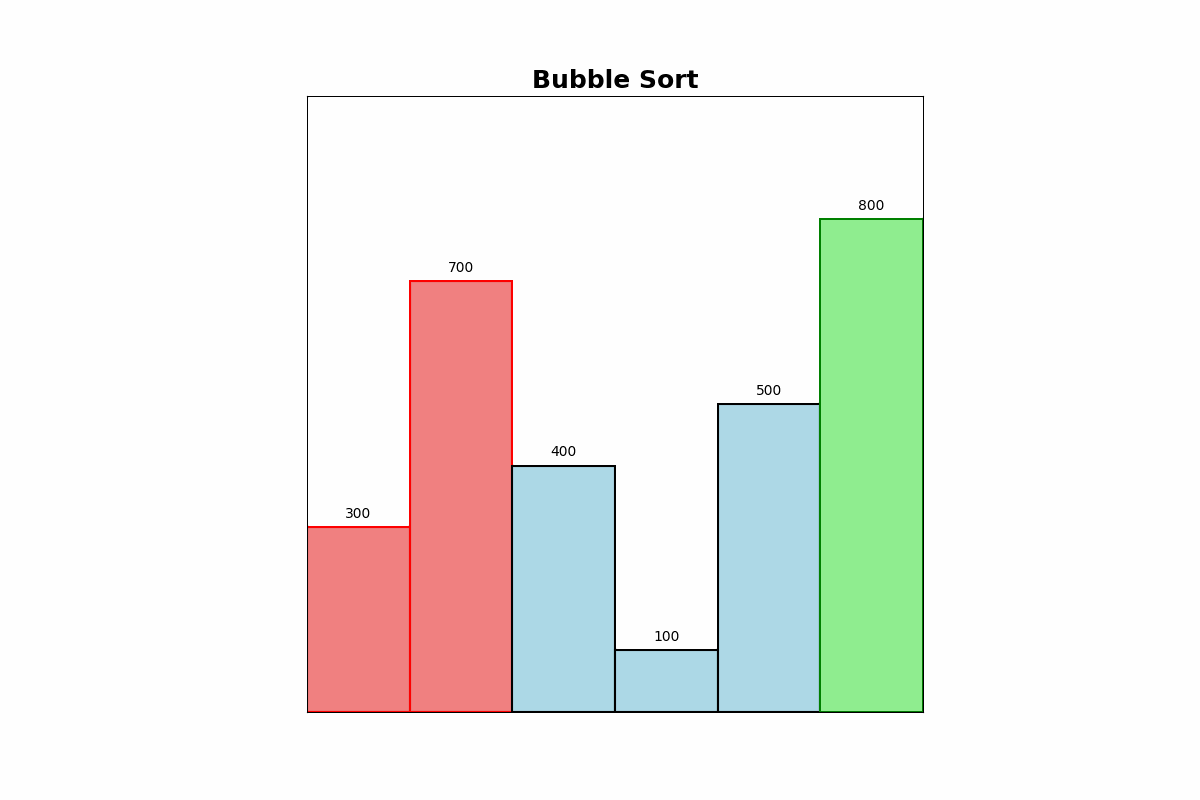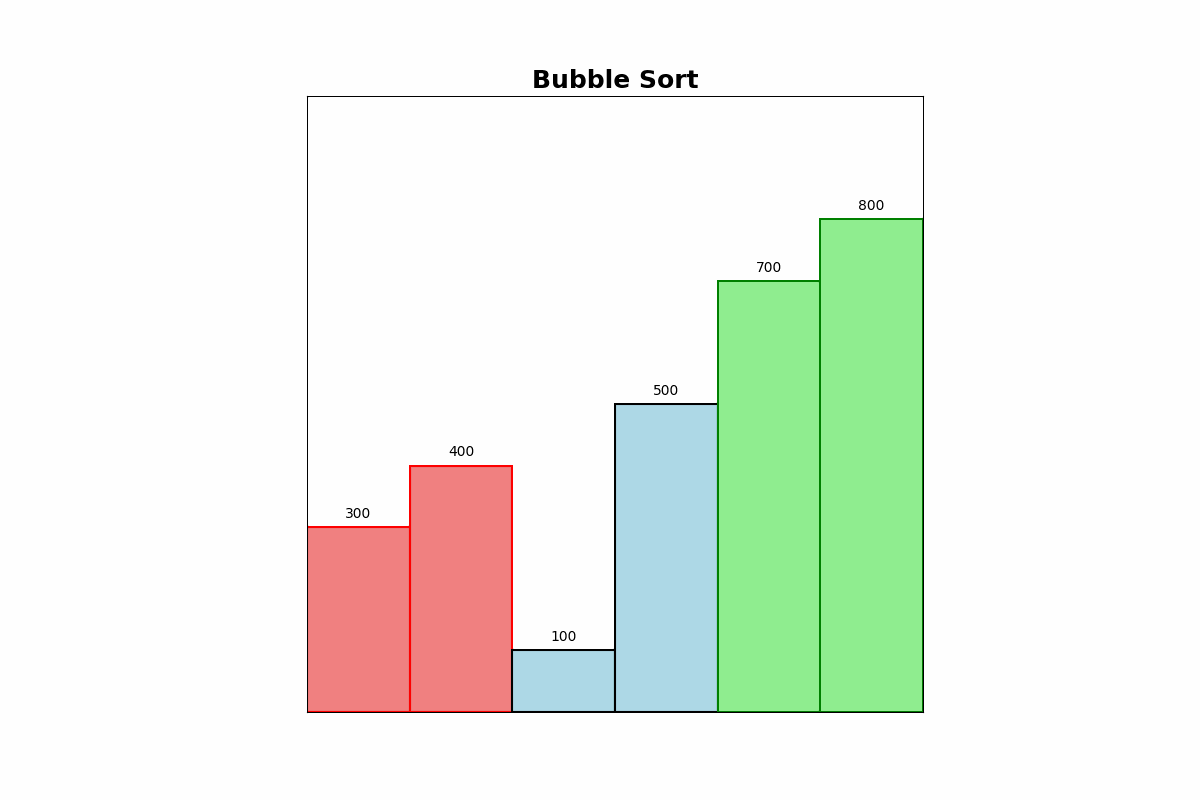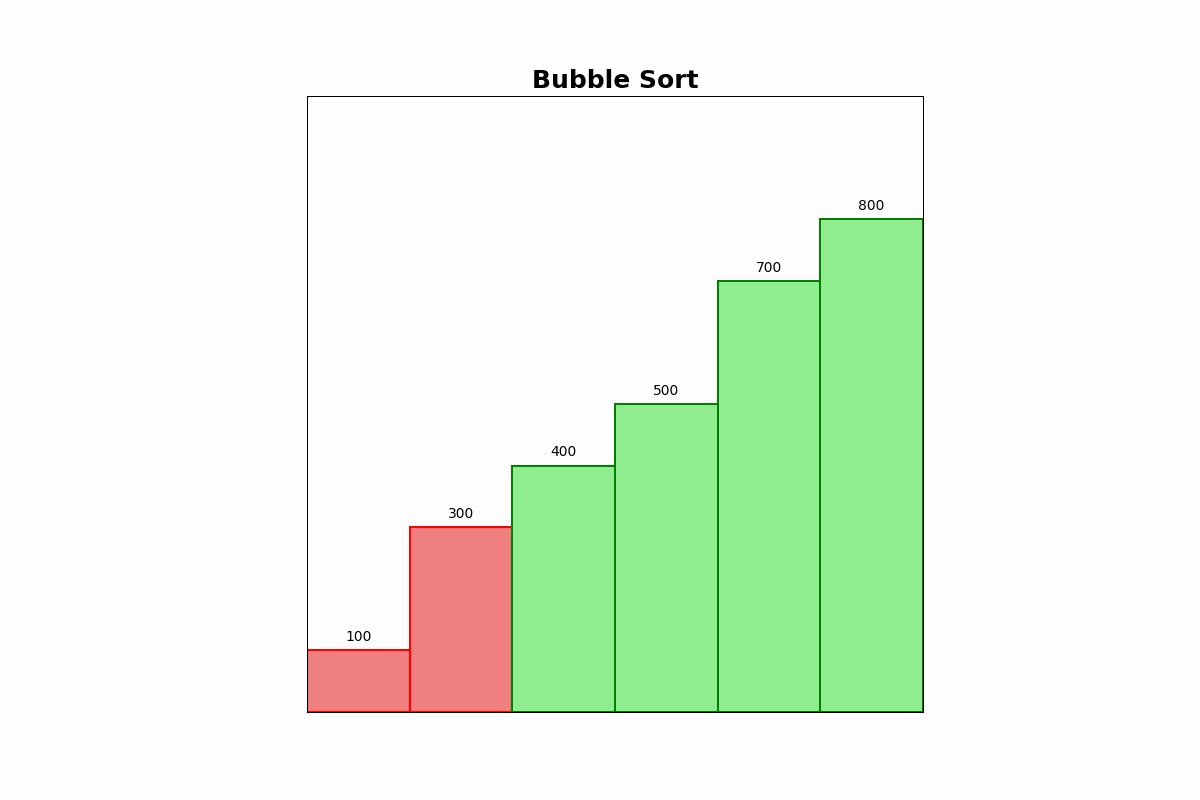
Use Cases:
Best for small datasets where simplicity is preferred.
Complexity:
Time Complexity: O(n²) in both average and worst cases.
Space Complexity: O(1) (in-place sorting).
Benefits:
Easy to understand and implement.
In-place sorting (no additional memory required).
Drawbacks:
Inefficient for large datasets due to quadratic time complexity.
Implementation:
public static void bubbleSort(int[] arr) {
int n = arr.length;
boolean swapped;
for (int i = 0; i < n - 1; i++) {
swapped = false; // Track if a swap has occurred
// Compare adjacent elements and swap if needed
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// Swap elements
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swapped = true; // Mark that a swap occurred
}
}
// If no elements were swapped, the array is sorted
if (!swapped) break;
}
}2. Selection Sort
Selection Sort repeatedly finds the minimum element from the unsorted portion of the list and swaps it with the first unsorted element. This process is repeated until the list is sorted.
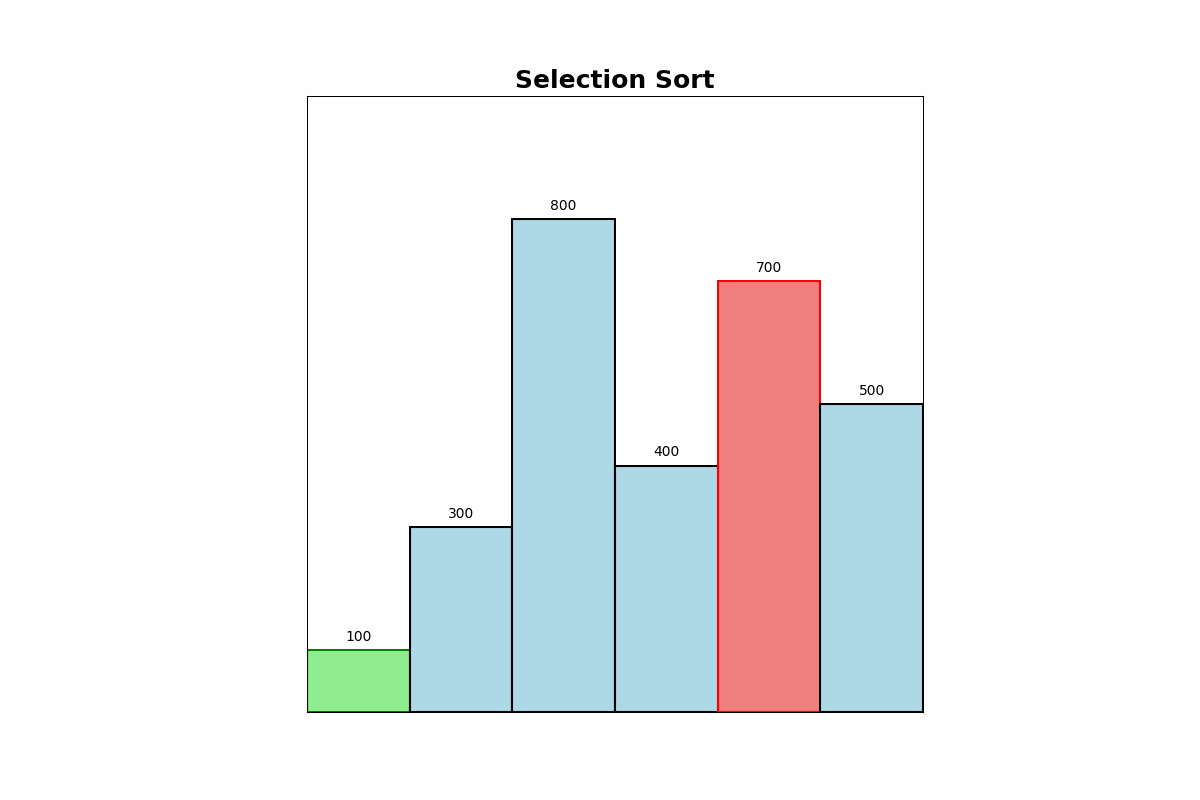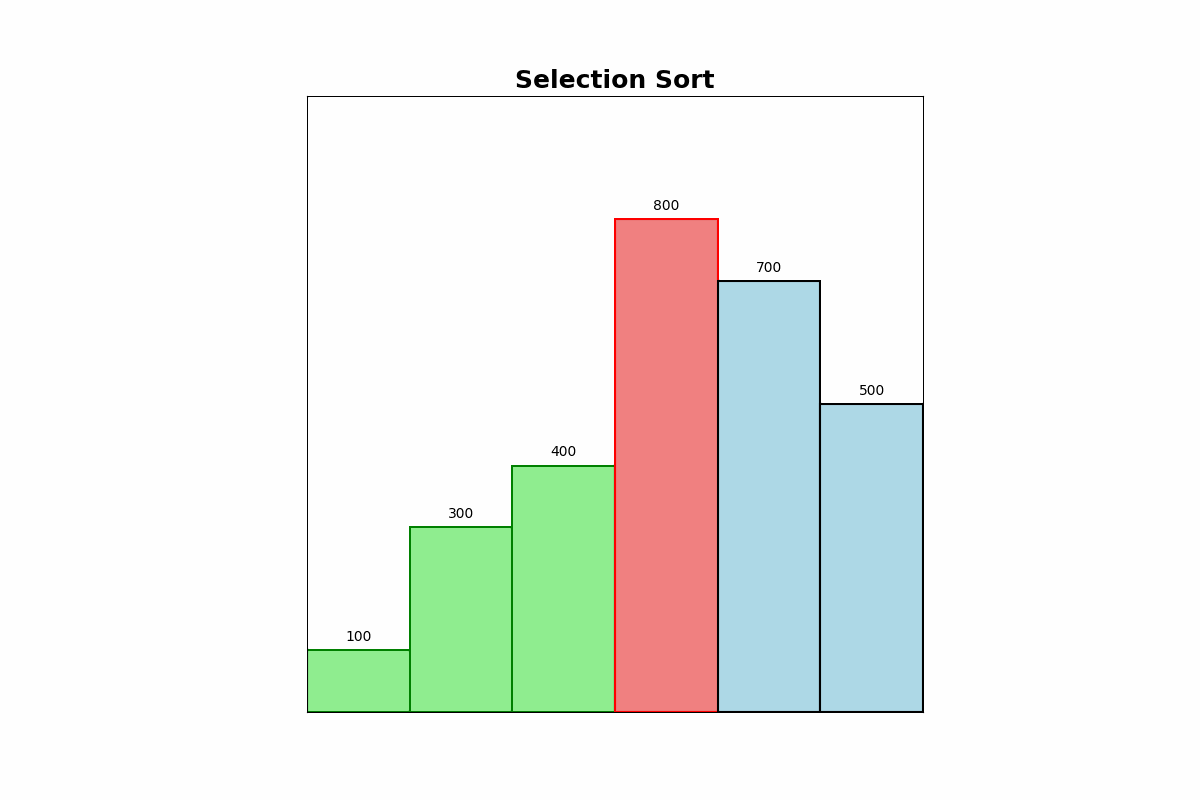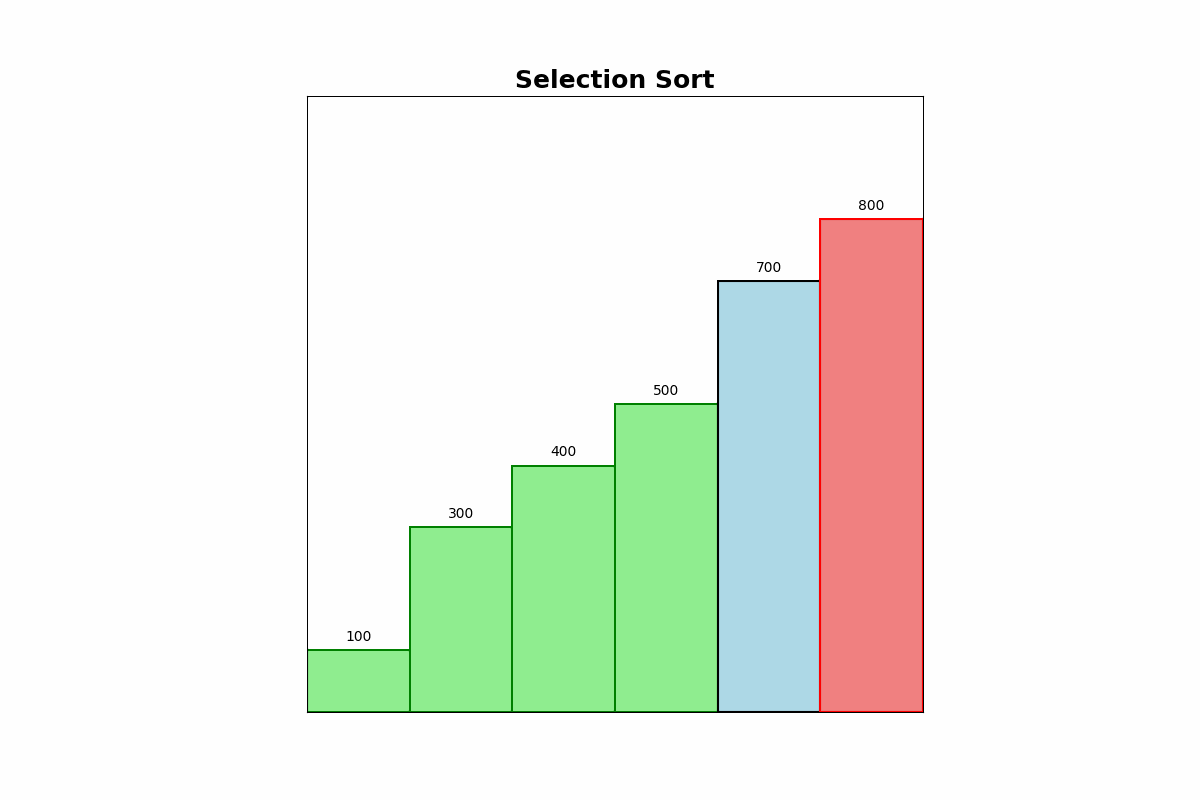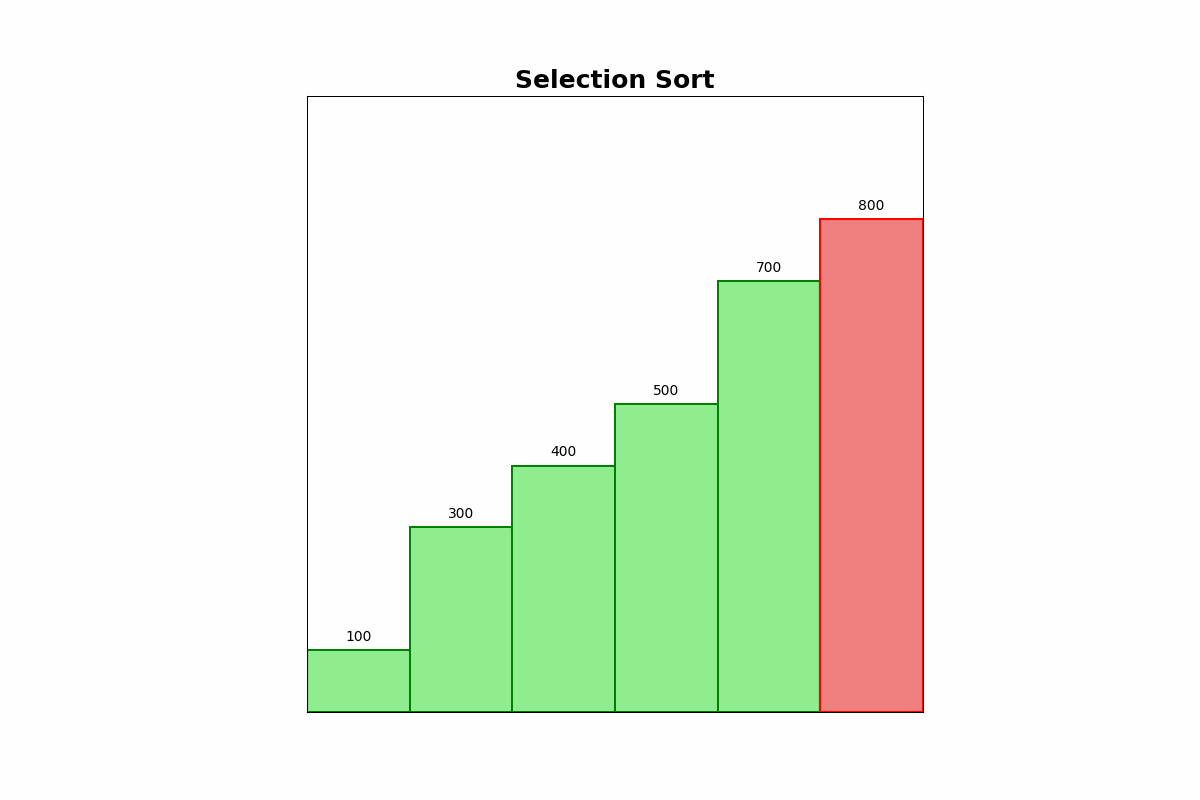
Use Cases:
Small to Medium Datasets: Suitable when memory usage is a concern.
Educational Purposes: Helps in understanding basic sorting mechanisms.
Complexity:
Time Complexity:
Best Case: O(n²)
Average Case: O(n²)
Worst Case: O(n²)
Space Complexity: O(1) (in-place sorting)
Benefits:
Simple to understand and implement.
Performs well with small datasets and minimal additional memory.
Drawbacks:
Inefficient for large datasets due to its quadratic time complexity.
Implementation:
public static void selectionSort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
int minIdx = i; // let current index is the minimum
// Find the index of the smallest element in the unsorted part
for (int j = i + 1; j < n; j++) {
if (arr[j] < arr[minIdx]) {
minIdx = j; // Update minIdx if a smaller element is found
}
}
// Swap the found minimum element with the element at index i
int temp = arr[i];
arr[i] = arr[minIdx];
arr[minIdx] = temp;
}
}3. Insertion Sort
Description: Insertion Sort builds the sorted array one item at a time. It inserts each new element into its correct position within the sorted portion of the array.
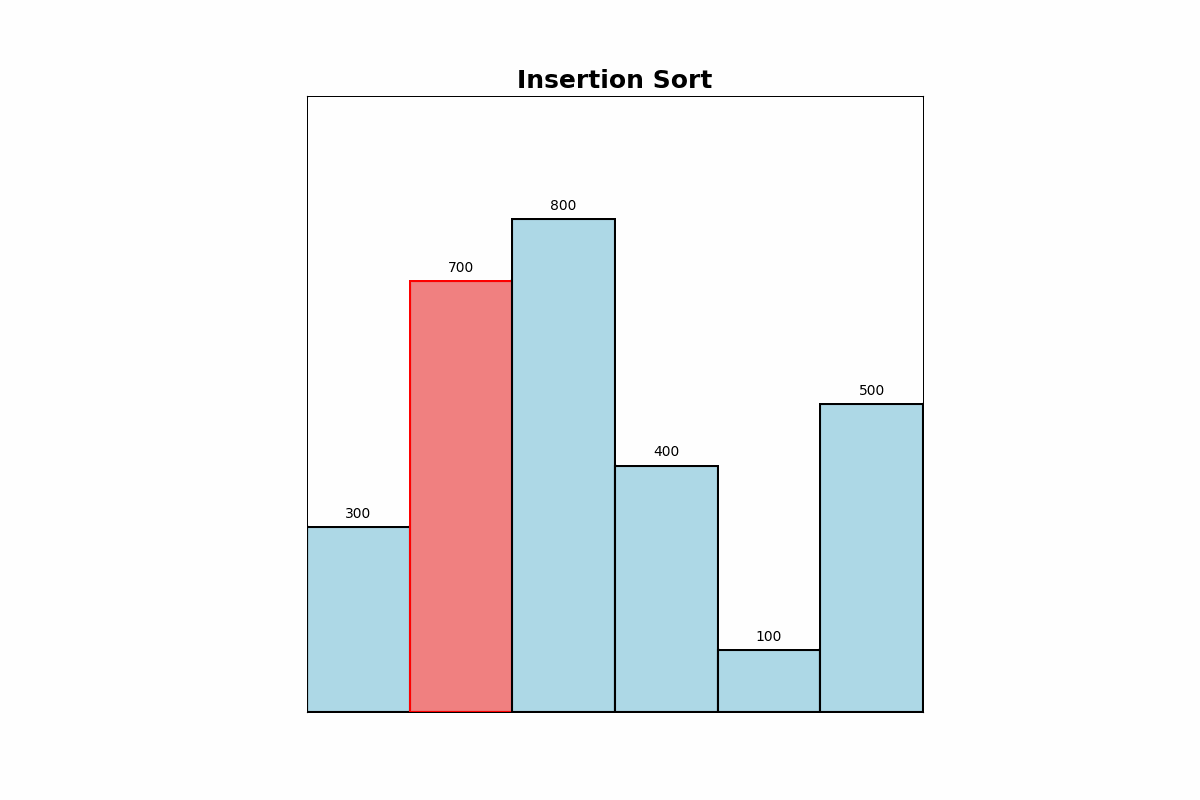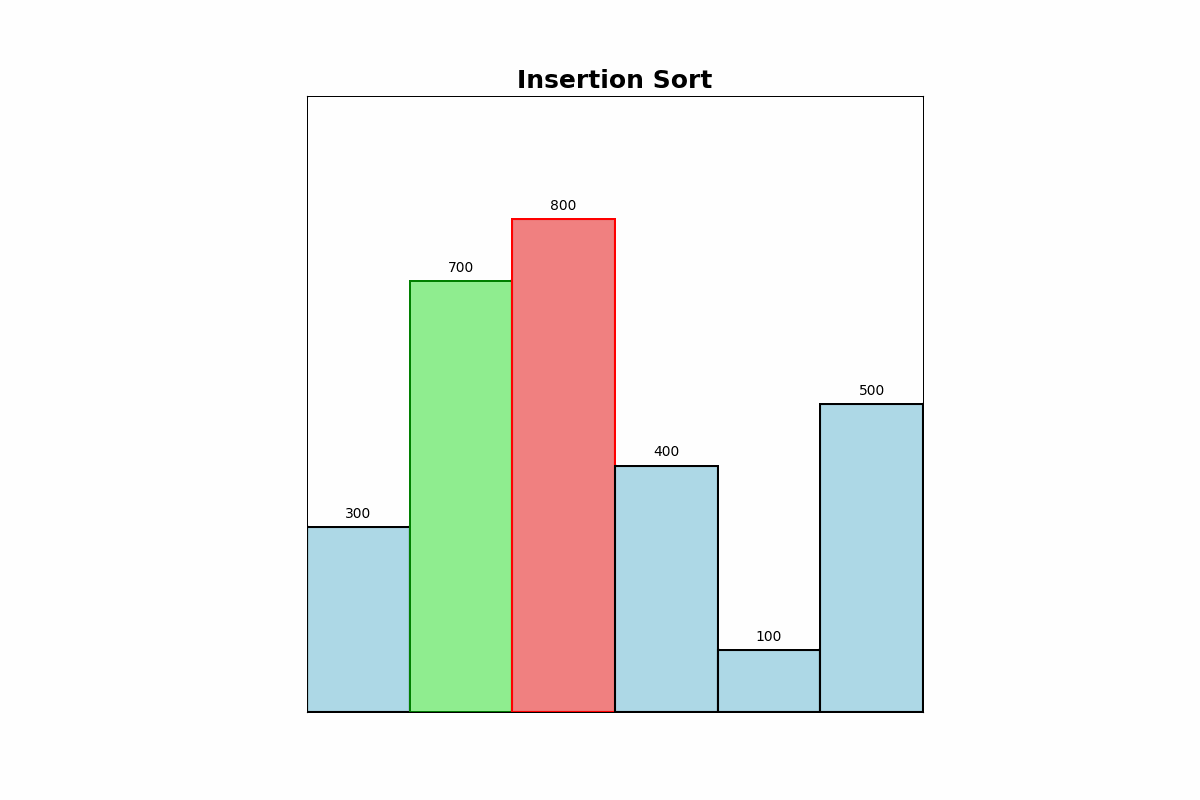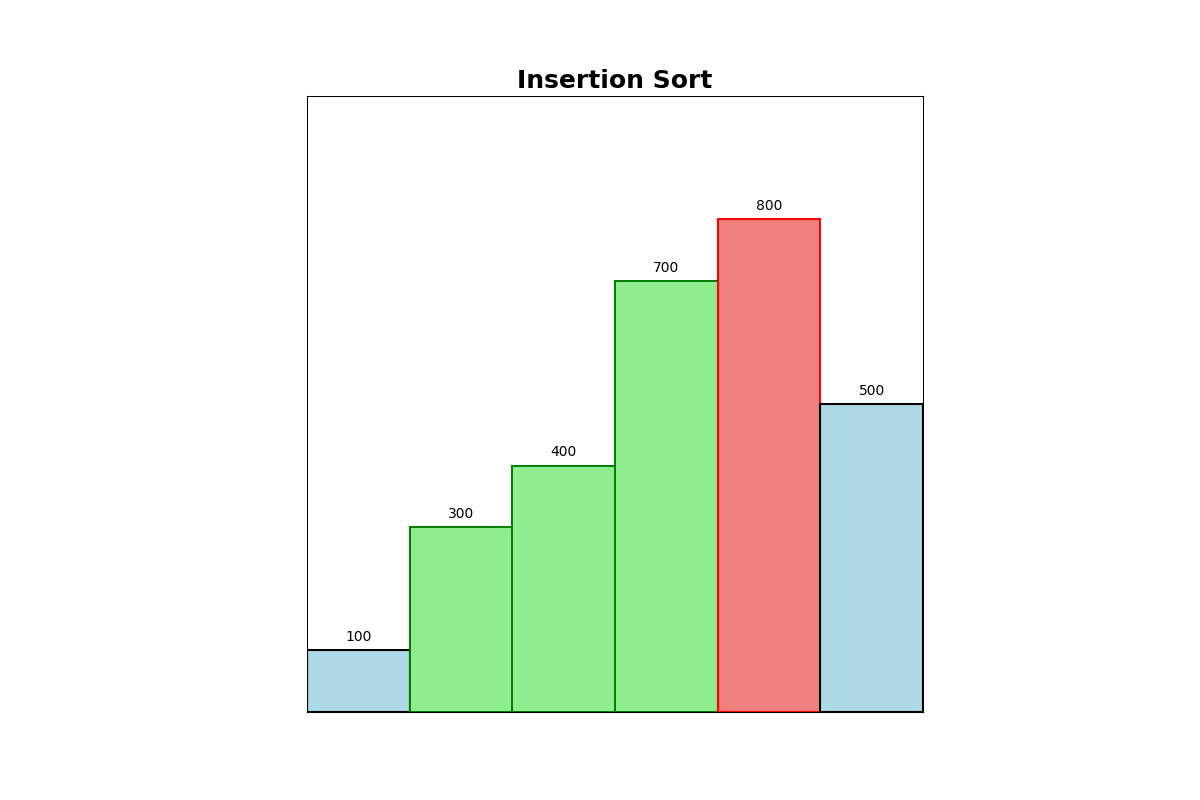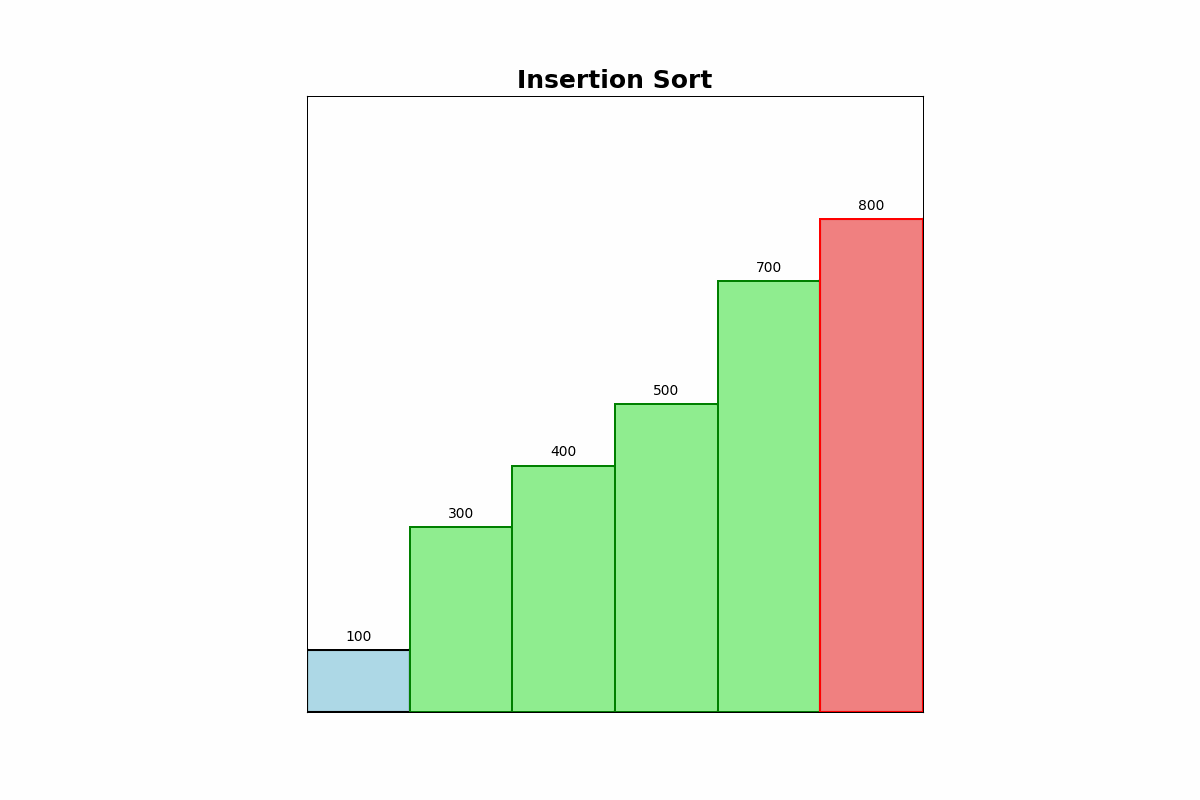
Use Cases:
Nearly Sorted Data: Efficient when the list is already mostly sorted.
Small to Medium Datasets: Performs well for small datasets and is practical for real-time applications where data arrives incrementally.
Complexity:
Time Complexity:
Best Case: O(n) (if the list is already sorted)
Average Case: O(n²)
Worst Case: O(n²)
Space Complexity: O(1) (in-place sorting)
Benefits:
Efficient for nearly sorted data or small datasets.
Simple to implement and understand.
Drawbacks:
Quadratic time complexity makes it less efficient for large, unsorted datasets.
Implementation:
public static void insertionSort(int[] arr) {
int n = arr.length;
// starting from index 1
for (int i = 1; i < n; i++) {
int key = arr[i]; // Element to be inserted
int j = i - 1;
// Shift elements of arr[0,,, i-1] that are greater than key
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
// Place key at its correct position
arr[j + 1] = key;
}
}4. Merge Sort
Description: Merge Sort divides the array into two halves, recursively sorts each half, and then merges the sorted halves to produce a sorted array.
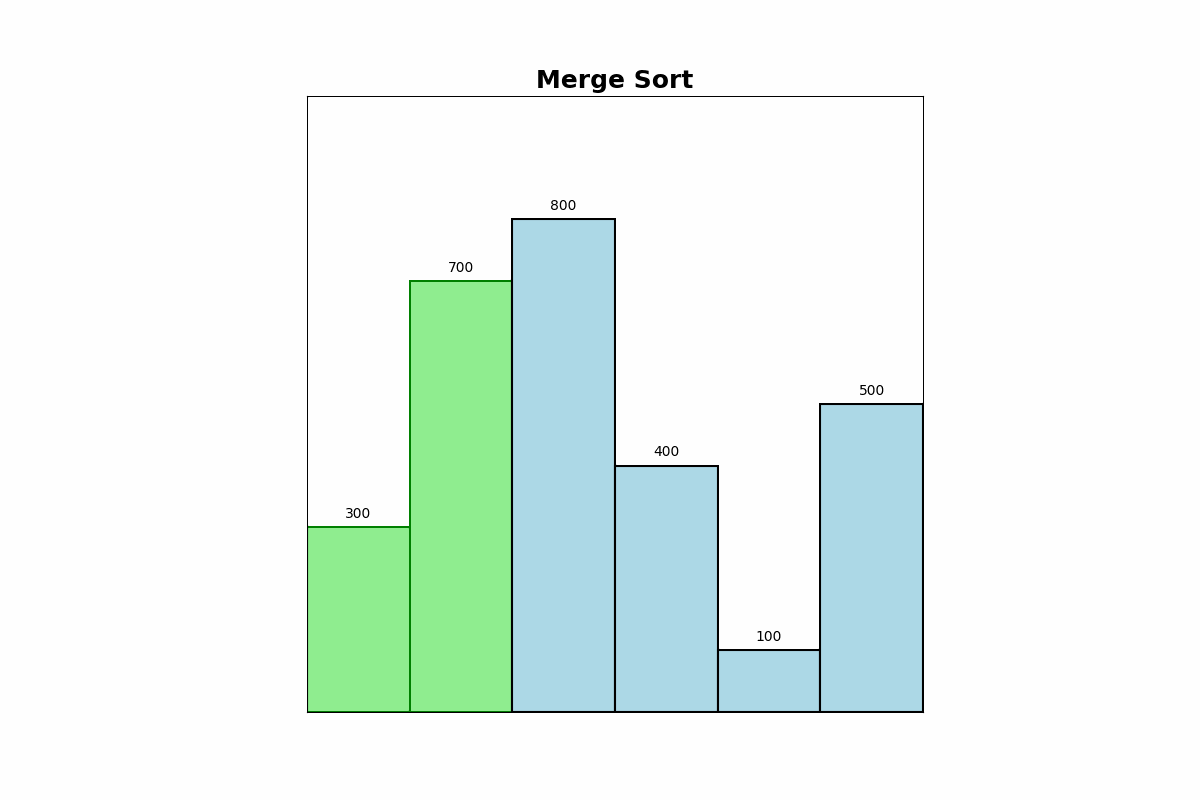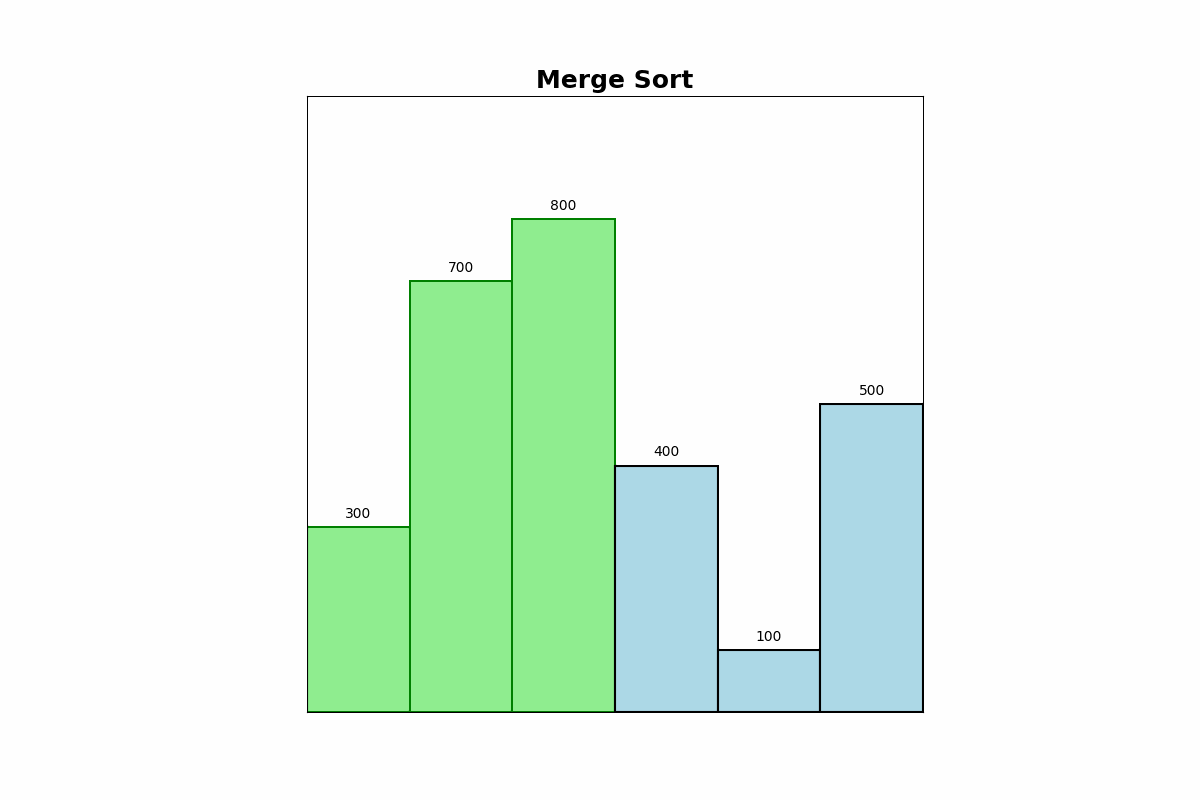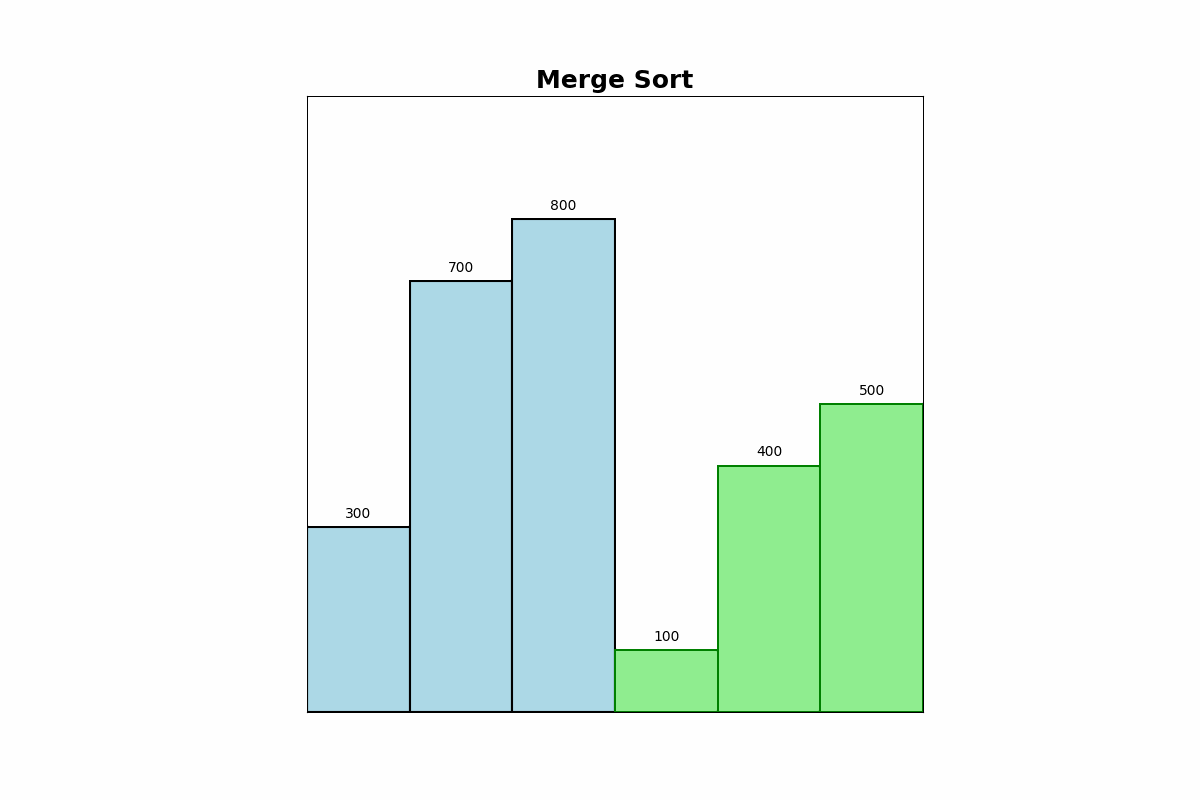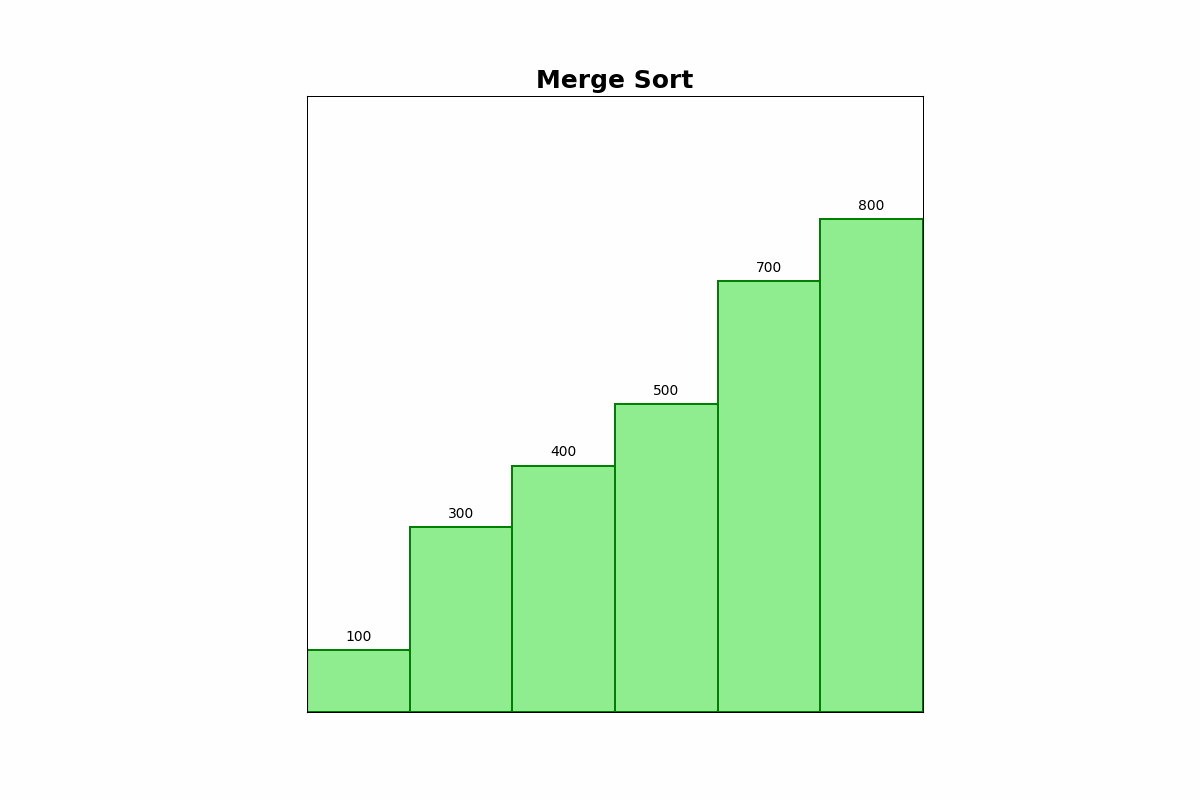
Use Cases:
Large Datasets: Suitable for sorting large datasets efficiently.
External Sorting: Ideal for scenarios where data does not fit into memory, such as large files.
Complexity:
Time Complexity:
Best Case: O(n log n)
Average Case: O(n log n)
Worst Case: O(n log n)
Space Complexity: O(n) (requires additional space for merging)
Benefits:
Consistent O(n log n) time complexity.
Stable sort (preserves the order of equal elements).
Drawbacks:
Requires additional memory for the merge process.
Implementation:
public static void mergeSort(int[] arr) {
if the array has less than 2 elements, it is already sorted
if (arr.length < 2) return;
// Locate the mid
int mid = arr.length / 2;
// Create subarrays for left and right halves
int[] left = new int[mid];
int[] right = new int[arr.length - mid];
// Copy elements to left and right subarrays
System.arraycopy(arr, 0, left, 0, mid);
System.arraycopy(arr, mid, right, 0, arr.length - mid);
// Recursively sort both subarrays
mergeSort(left);
mergeSort(right);
// Merge the sorted subarrays
merge(arr, left, right);
}
private static void merge(int[] arr, int[] left, int[] right) {
int i = 0, j = 0, k = 0;
// Merge elements from left and right subarrays into arr
while (i < left.length && j < right.length) {
if (left[i] <= right[j]) {
arr[k++] = left[i++]; // Insert from left
} else {
arr[k++] = right[j++]; // Insert from right
}
}
// Copy remaining elements from left subarray, if any
while (i < left.length) {
arr[k++] = left[i++];
}
// Copy remaining elements from right subarray, if any
while (j < right.length) {
arr[k++] = right[j++];
}
}5. Quick Sort
Description: Quick Sort selects a pivot element, partitions the array into elements less than and greater than the pivot, and recursively sorts the partitions.
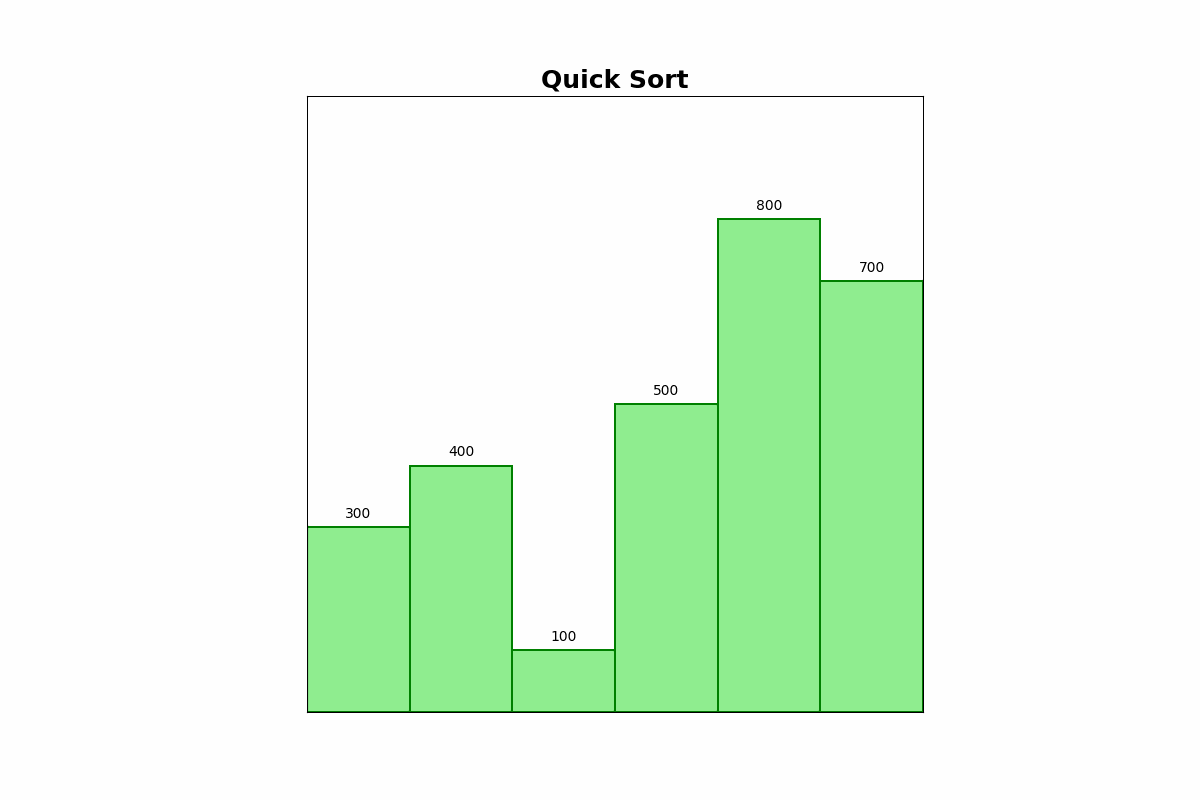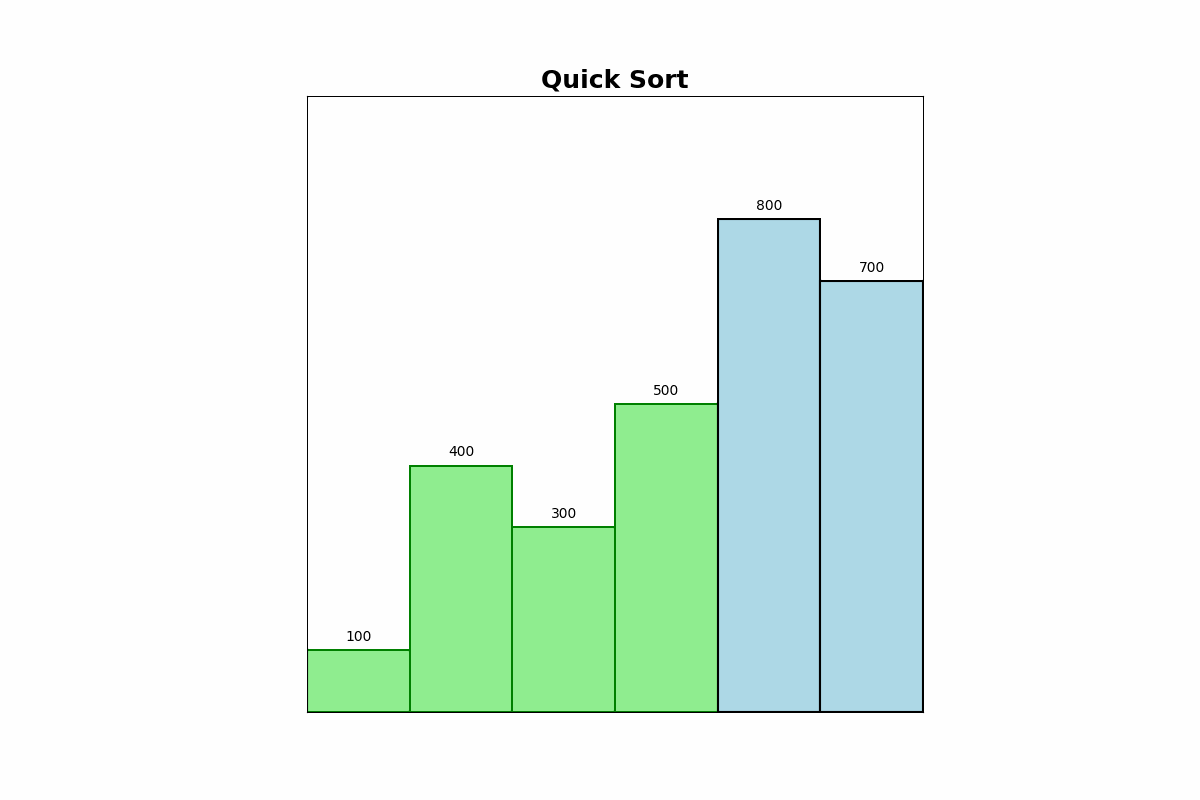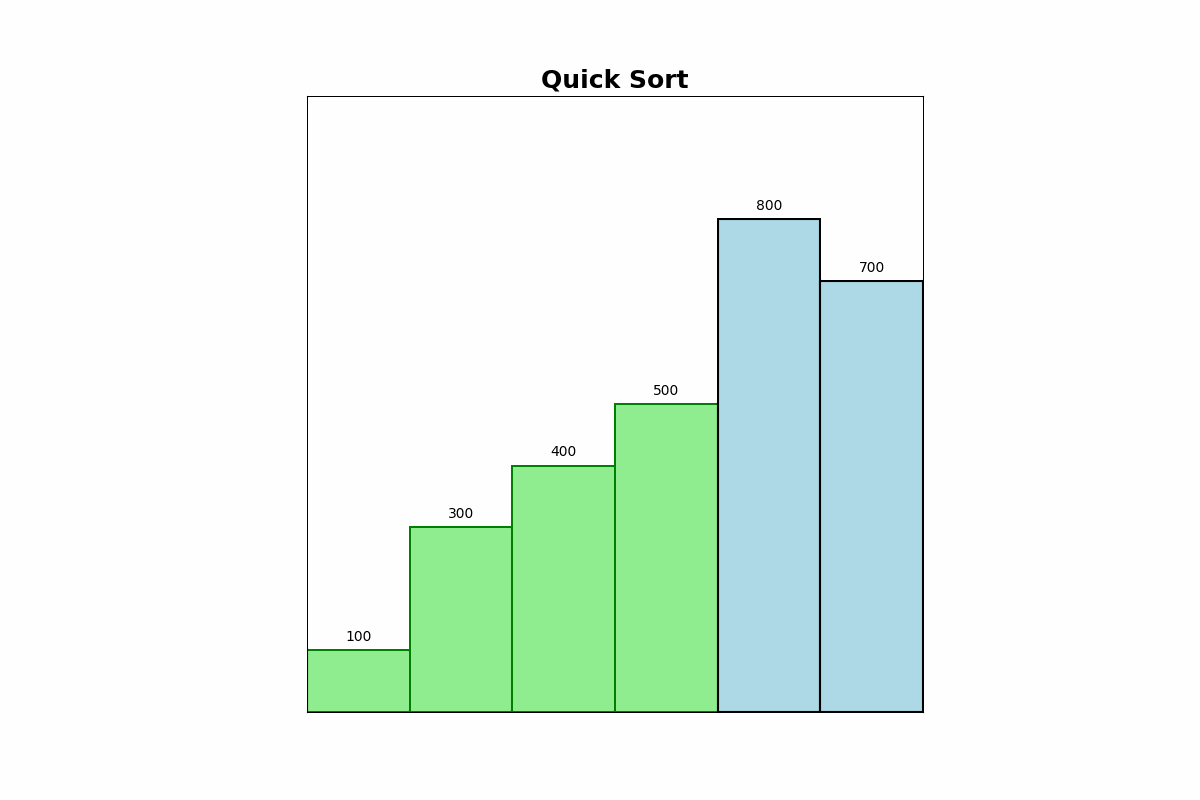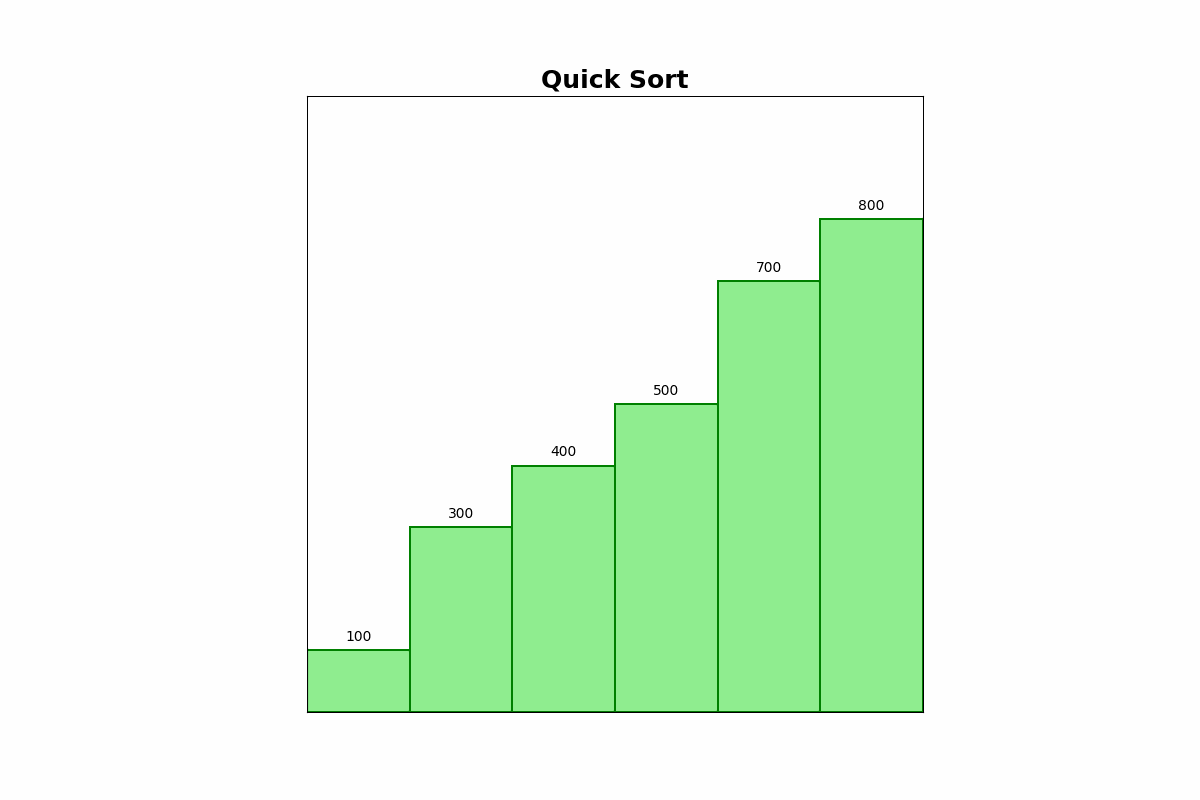
Use Cases:
Large Datasets: Efficient for in-memory sorting of large datasets.
General Purpose: Often used in practical applications due to its average-case efficiency.
Complexity:
Time Complexity:
Best Case: O(n log n)
Average Case: O(n log n)
Worst Case: O(n²) (can be mitigated with good pivot selection strategies)
Space Complexity: O(log n) (average recursion stack space)
Benefits:
Generally faster than Merge Sort for in-memory sorting due to lower constant factors.
In-place sorting with good average-case performance.
Drawbacks:
Worst-case performance can be O(n²) if not optimized with strategies like random pivot selection.
Implementation:
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
// Partition and get the pivot index
int pi = partition(arr, low, high);
// Recursively sort elements before and after the pivot
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
// Partitions the array and place pivot in correct position
private static int partition(int[] arr, int low, int high) {
int pivot = arr[high]; // Pivot element
int i = (low - 1); // Index of smaller element
for (int j = low; j < high; j++) {
if (arr[j] <= pivot) {
i++;
// Swap if element is smaller than or equal to pivot
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// Place pivot in the correct position
int temp = arr[i + 1];
arr[i + 1] = arr[high];
arr[high] = temp;
return i + 1; // Return pivot index
}Summary
Bubble Sort: Simple, but inefficient for large datasets (O(n²) time complexity).
Selection Sort: Simple and in-place, but also inefficient for large datasets (O(n²) time complexity).
Insertion Sort: Efficient for small or nearly sorted datasets (O(n²) time complexity in worst case, O(n) in best case).
Merge Sort: Efficient and stable with O(n log n) time complexity, but uses extra space (O(n) space complexity).
Quick Sort: Efficient with average O(n log n) time complexity, but can degrade to O(n²) in worst case.
If you found this post helpful, consider subscribing for more updates or following me on LinkedIn, and GitHub. Have questions or suggestions? Feel free to leave a comment or contact us. Happy coding!!